MR-Runner - The MapReduce Runner
Synopsis
mrrunner COMMAND [OPTIONS]
Commands
start -l <LEVEL> -f <jdf> : configure and deploy an MR cluster
list : list the active MR clusters
master <clusterID> : get the master node of an MR cluster
stop <clusterID> : stop the MR cluster with the given clusterID
LEVEL = FATAL|ERROR|WARN|DEBUG|INFO
Description
The MR-Runner deploys MapReduce (MR) clusters on demand over the DAS-4 system. The MR-Runner is implemented in Java and currently configures Hadoop-1.0.0 clusters. KOALA is responsible for scheduling jobs, which in this case are complete MR clusters, received from the MR-runners. Based on the desired size (number of nodes) of the MR cluster, KOALA schedules the job on the adequate physical cluster by applying one of its placement policies.
-
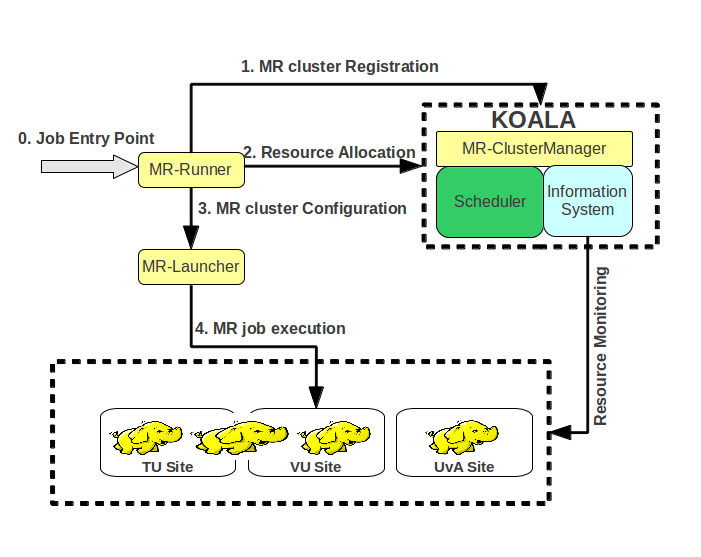
- The Koala MR-Runner System Architecture
Setup
1. Create your own Job Description File:
+(&
( count = "40")
( maxWallTime = "30" )
( resourcemanagercontact = "fs3.das4.tudelft.nl" )
)
count = the size of the MapReduce cluster (number of machines x 8 processors)
maxWallTime = the duration of the SGE reservation in minutes
resourcemanagercontact = preferred execution site
2. Configuration and log files:
Hadoop configuration files path: ~/.mrcluster/<clusterID>
Hadoop log files path: ~/var/scratch/$USER/logs/
3. Executing Hadoop commands:
All Hadoop commands are executed on the master node of the MR cluster:
e.g. ssh <masterNode> /home/koala/hadoop/bin/hadoop --config ~/.mrcluster/<clusterID> dfs -ls /data
Big Data Processing System
The MR-Runner enables access to the following stack of frameworks for big data processing:
- Storage layer: Hadoop Distributed File System
- Execution engine: Hadoop MapReduce
- Query language: Pig
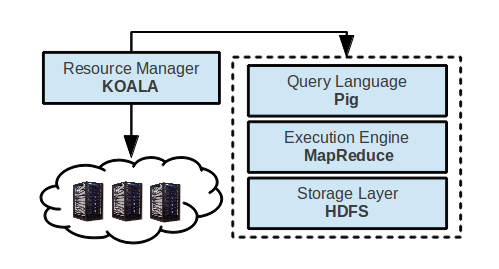
- Koala-based Big Data Processing System
KOALA News
- January 2013: MR-Runner upgraded! Now the MR-Runner deploys Hadoop-1.0.0 clusters, compatible with Pig-0.10.0.
- December 2012: KOALA 2.1 released! Deploy MapReduce clusters on DAS-4 with the Koala MR-Runner.
- November 2012: Best Paper Award at MTAGS12 workshop (co-located with SC12) with work on MapReduce!
- November 2009: KOALA 2.0 released! You can now run Parameter sweep applications (PSAs) with KOALA CSRunner.
- April 2008: New KOALA runner! The OMRunner enables DRMAA and OpenMPI job submissions.
- July 2007: Paper accepted at Grid07 conference with work on scheduling malleable jobs in KOALA.
- May 2007: KOALA has now been ported successfully to DAS-3. All the KOALA runners are operational apart from the DRunner.
- April 2007: The KOALA IRunner has been updated to include recommendations made by the Ibis group .

